Blog
Predictive Lead Scoring with Python
How to build a lead scoring model that actually serves stakeholders

What is Lead Scoring?
As companies grow, inevitably the number of inbound leads coming in exceeds the capacity of the sales team to respond quickly. Naturally, one of the tools sales leaders often look for is a lead scoring methodology, and the data teams are asked to help. If you’ve wondered what lead scoring is or why we do it then this post is for you.
I'll outline what lead scoring is, why it matters, and how to think about implementing it, along with a few different methods and some tips on making the most out of it.
First, we'll start with a scenario to help guide our discussion.
Imagine you are a data scientist at a fast-growing software company with a product-led growth motion. Your VP of Sales approaches you to ask for help. The volume of leads coming through inbound channels has skyrocketed ever since a famous influencer tweeted about how great your product is. Now your sales reps have more leads than they know what to do with. Unfortunately, your VP of Marketing accidentally turned on paid ads before going on vacation to Burning Man and can't be reached to wrangle the flood of new users trying out your product.
You need a way to sort the wheat from the chaff. You wonder, what even is chaff? After a 15-minute detour through Wikipedia, you arrive ready to tackle this problem. But where to begin?
Four Key Questions to Ask Before You Build Lead Scoring Models
The worst thing you can do is jump head-first into predictive modeling without fully understanding the business context. I know you're just itching to fire up a Python notebook and start importing fourteen different modules from sklearn. We all are. But first, let's think carefully about what we're trying to achieve.
There are four key questions to ask yourself before you start this lead scoring project:
Who are you creating the predictive model(s) for?
How will they use it?
What data will you use, and what data will you exclude?
How will you know if it's working?
Let's tackle these one at a time.
Who Is This For?
First, who are you building this predictive lead scoring model for? After talking to the VP of Sales to understand how he plans to use the scores, you learn that your sales development reps, or SDRs, will use the lead score to prioritize the deluge of leads in your CRM.
Right now, they are using their internal heuristics to decide who to reach out to, but this has led to missed opportunities and inconsistent results from one person to the next.
There are far too few SDRs right now for the number of leads. Their typical workflow is scanning a large list, looking for something that stands out, and then emailing those leads with a custom message to get them to respond. As a result, they are stressed, overwhelmed, and constantly worried that they've missed something critical.
How Will They Use the Lead Scores?
A good lead scoring model will be something that the SDRs can use as a quick heuristic. Therefore, the team needs to understand and believe in the model you build. Otherwise, they will ignore it and continue as they have been.
If they trust the score, they will use it by sorting their inbound list by the score in descending order. While the SDRs might not go through every lead in the exact rank order, the ranking will help them better separate good leads from bad ones and give them more confidence that they haven't missed anything.
Another step is ensuring they respond to the highest scoring leads as quickly as possible. A stale lead doesn't tend to respond, so the highest-ranking leads tend to get the most attention as soon as possible.
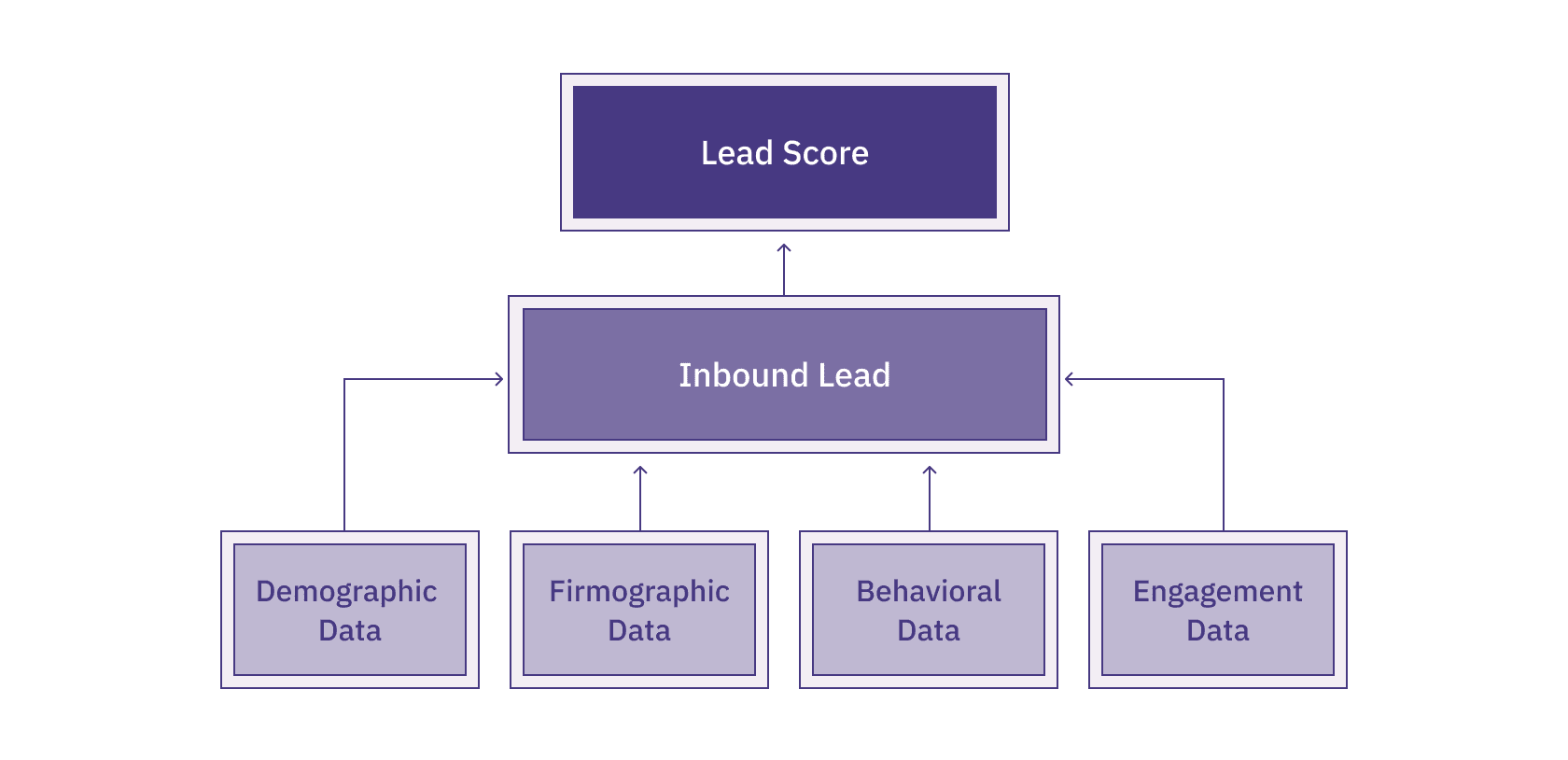
What Data to Use for Lead Scoring?
There's a wealth of data, from demographic and firmographic data to behavioral and engagement data. Instead of trying to find and wrangle every possible bit of information, you decide to interview the SDRs to understand their heuristics better. They tell you the highest signal pieces of data they use are the size of the company (number of employees and revenue), the industry, the role, and whether they've engaged with us through marketing efforts such as a conference or a whitepaper.
How Will You Know if Your Lead Scoring Model Works?
Another critical question is figuring out how you will know if your model works. For example, your model will run daily to calculate scores for all inbound leads, so you decide to save the historical scores. Then, in a few weeks, you'll run an analysis to see the average score of leads that the SDR team reached out to daily. You'll also compare the conversion rate of all leads against your predicted score to help you understand which SDRs are using your scores.
With this information in hand, you can start planning your approach.
Building a Predictive Model
We'll go through six steps to build our predictive model now that we're armed with insights from our stakeholders. We'll cover the following:
Collecting the Data
Training the Model
Assessing Performance
Sharing Results
Iterating
Deploying
Collecting the Data
When collecting data, it's critical to watch out for data leakage. Look for features in your dataset that are correlated with the outcome or that you won't have access to during live predictions. For example, you might have preliminary data on demographic and firmographic attributes when a lead comes in. These likely don't change, but you don't want to use features such as 'last_emailed_by_sales_rep' as that is probably highly correlated with whether or not a person converts, but that's not a helpful predictor! Remember, we're trying to predict whom a salesperson should reach out to, so no one would have been contacted yet when lead scoring happens.
Having good historical data can show its worth here. For example, you might look at website and product activity only before the first outbound contact was made. If you're unsure of something, it's often safer to exclude it. If your model looks too good to be true, or if one predictor has an outsized influence on the model, it might be better to remove it.
Don't settle for readily available data, like the number of employees or roles. While that data is important, it can be helpful to think more holistically about the problem space. For example, perhaps you can create features such as when they last visited the pricing page or how many high-intent activities they performed in your application.
Training the Model
Now, we can start training our model, but one of the issues with training your model is finding the right place to get started. Playing with virtual environments and getting Jupyter to recognize the right one can be a pain. Even something seemingly simple, connecting to your warehouse to download data, can be convoluted. A collaborative notebook application like Hex can help make it quicker to start.
With Hex, warehouse credentials can be set globally and are always available. You also never need to mess with virtual environments again.
For this example, I created some fake data representative of some leads that a B2B SaaS company might have captured from various sources. Turns out most companies don’t want to make all their leads publicly available, very strange!
It's easy to upload a CSV and start operating on it using SQL or Python. However, if you're using data from your data warehouse, you can just as easily connect and start working on actual data.
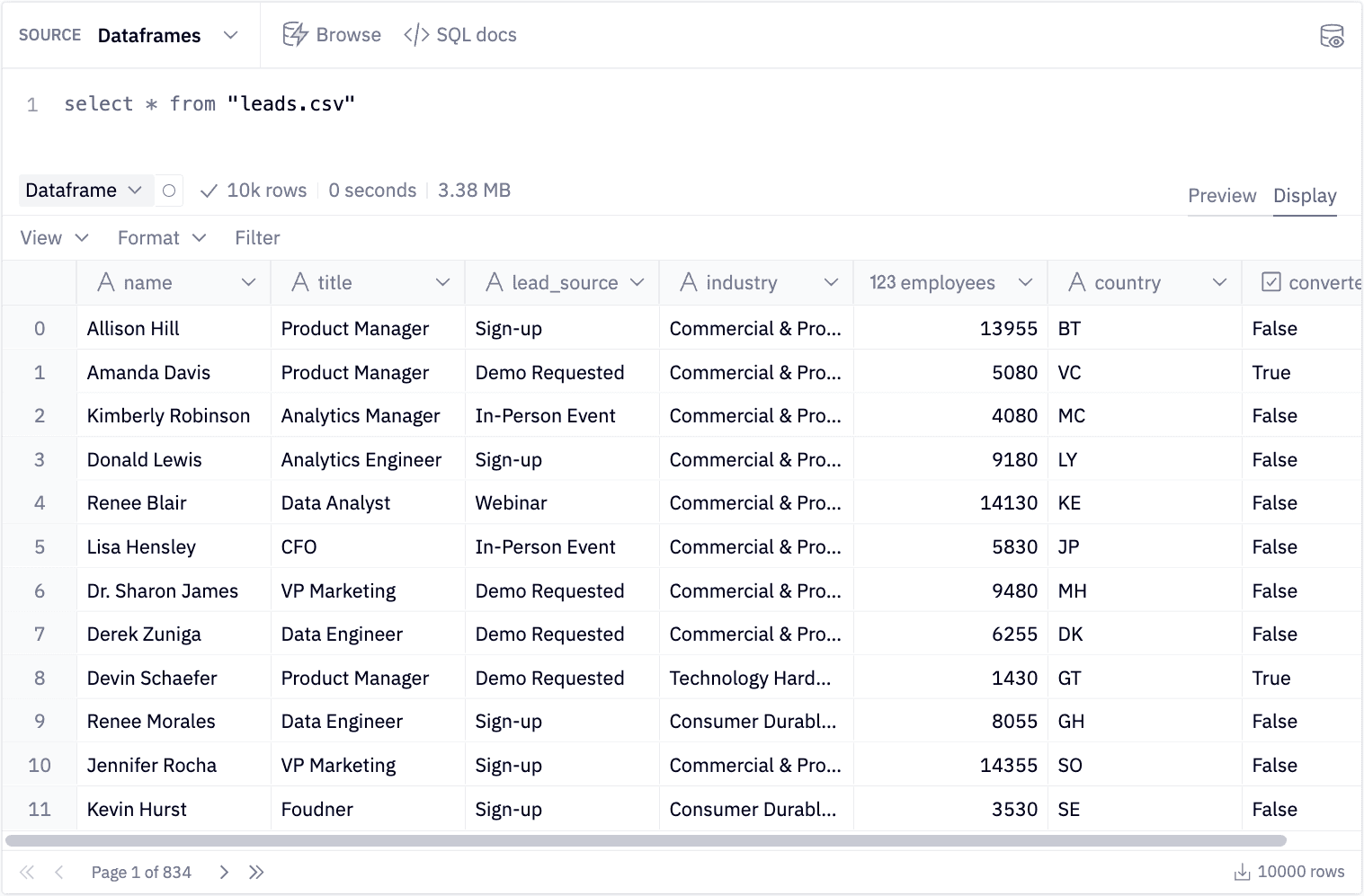
Our data includes the names and titles of people who might be interested in buying our product. We captured where the lead was sourced from, such as a webinar or application sign-up. We also have information on their company, such as the industry, the number of employees, and country. We also have a flag for whether or not this lead converted.
I like to start with a simple baseline model. In this example, I talked to our SDRs and they mentioned that they see the greatest traction from engineers who came from the sign-up flow. Let’s build that model first.

I've also calculated some performance metrics, which we'll dive into in the next section. Suffice it to say that these results are pretty bad! Our accuracy is not much better than chance. Still, it's good to have a simple baseline to measure yourself against. If we can't beat these poor results, we might as well give up and change careers to be a data influencer instead.
Creating a Decision Tree
We want to increase the complexity of our modeling slowly. Before diving into neural networks, let's see what improvements a decision tree can give us. Decision trees are a good start because they are highly interpretable. If the performance is good, we might prefer it over better performing but harder to interpret models. Remember, we don't just want good performance; we want to build trust with our team! We can always move to more complex models once we've earned that right.
To tune our model, we'll perform typical data science modeling techniques, like cross-validation and grid-search. We are now operating on training and test sets to ensure we have representative performance measures. Our hand-rolled algorithm didn't need a train or test set since our 'model' required no tuning.

We can run the same performance measures against our decision tree results and see how they compare.

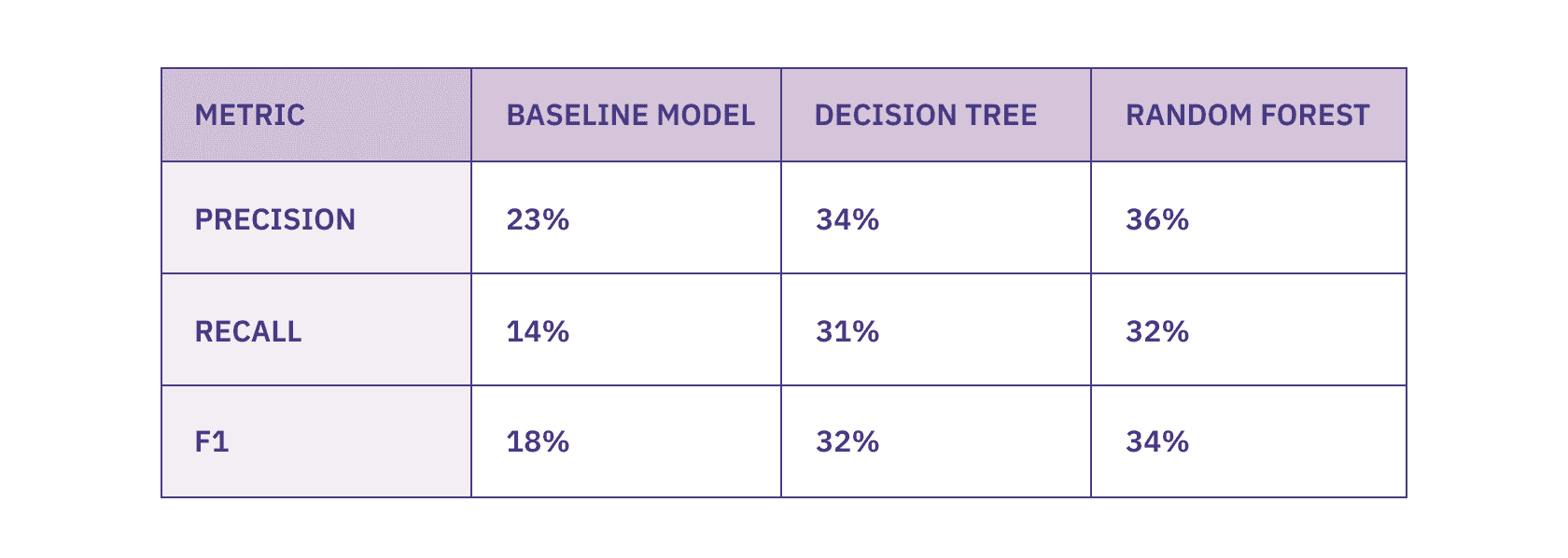
We can see improvement across nearly all our metrics! Great news! Maybe Data Science isn't dead after all? Our F1 score increased from 18 to 32, our precision increased from 23% to 33% and our Recall increased from 14% to 31%. Seeing improvements in both precision and recall is particularly exciting since it means we aren’t just trading one off against the other, but seeing material improvements in the model performance.
We can take it one step further and plot the decision tree to see what types of decisions it makes.
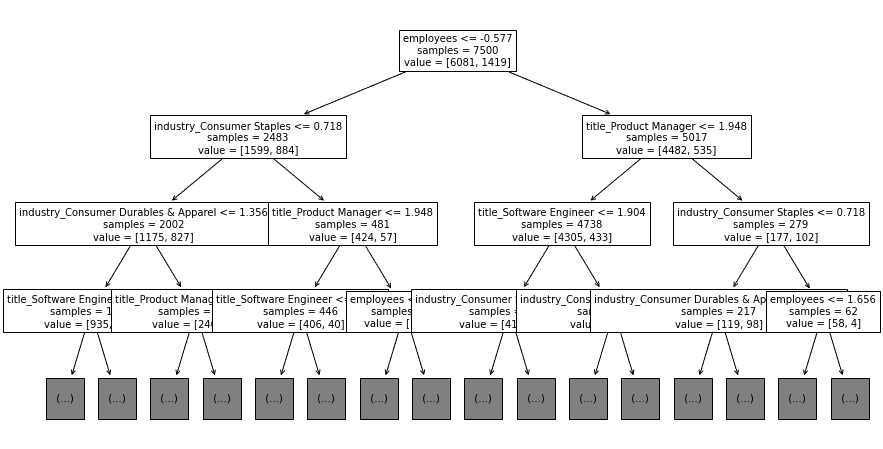
I won't cover how decision trees work, it should be reasonably straightforward here. The model clearly thinks the number of employees is a great predictor, and then it breaks predictions down by title and industry.
We can keep iterating like this with more and more complex models. For example, we might try random forest, believing that smaller trees might be more predictive than deeper ones, or we might try gradient-boosted machines.
As an example, I’ve trained a random forest model to see if performance improves with a more complex model.

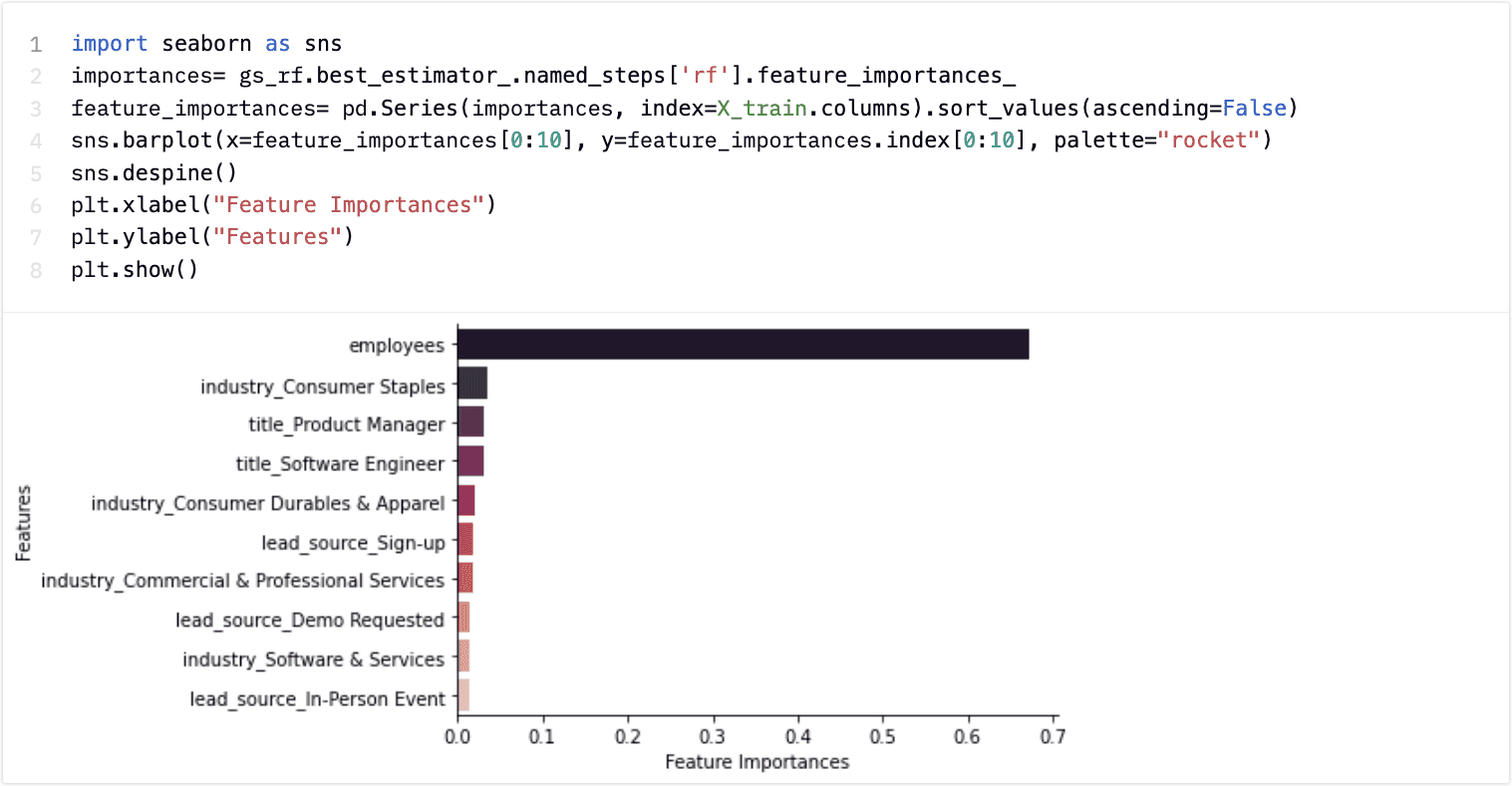
We can see some marginal improvements in performance but at a greater cost of interpretability. In a Random Forest model, we don’t have access to exactly how a decision is made, but we can plot how important various variables are to the overall model.
By plotting a feature importance plot, we see how important the number of employees is to the quality of our leads. This matches our intuition from the decision tree plot but is also interesting to note that this wasn’t the main feature our SDRs mentioned when discussing what they think is important.
We could continue down this path of model tuning and selection, however, instead of covering every possible ML model, let's think carefully about performance metrics since this is often overlooked.
Assessing Model Performance
There are many different model performance metrics, and there's never a single correct choice. So let's think of how we can be right and wrong first. There are two ways we can be wrong: we either rank someone highly who isn't going to convert, or we categorize someone low who would've converted. Which is the greater sin?
The cost of reaching out to someone who doesn't convert is much lower than the cost of not reaching out to someone who would've converted! So in our model, we might want to optimize for fewer False Negatives over False Positives.
Precision is the level of confidence we can have in our predictions. Precision is the ratio of True Positive cases over all Predicted Positive cases. Precision helps our SDRs gain confidence in our predictions. If we say that we have 75% precision in our model, that means three people will convert for every four that we say you should contact. That's pretty great!
Recall is the lost opportunity metric. Of all the people who were likely to convert, how many of them did we predict would convert? Again, we don't want this number to be too low; otherwise, it means there will be many hidden gems in our leads that would become customers.
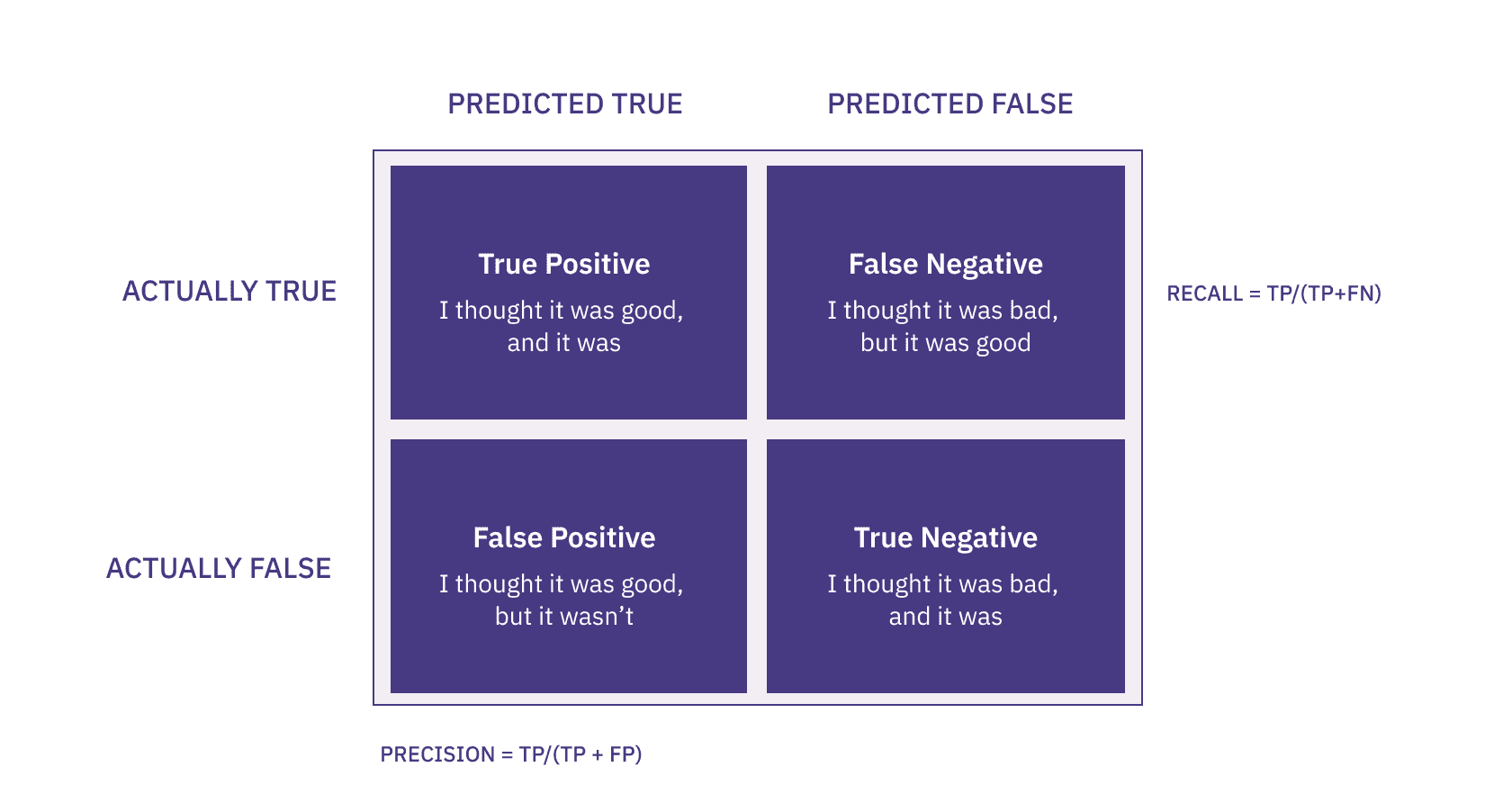
How can we balance Precision and Recall? We can use the F1 score, which balances these metrics by calculating the harmonic mean between the two.
Now that we understand our metrics, let's compare our scores for the various methods. Our Random Forest model has the highest F1 score, and we can see it does marginally better on Precision and Recall than our Decision Tree. The good news is that both models completely crush our baseline model (phew).
Ultimately, which model we choose will depend on various factors, but explaining how you trained a model and your trade-offs can help establish confidence with the rest of your team and stakeholders.
Share Your Results
Once you've built your initial model, you'll want to spend some time creating some additional artifacts that help tell the story. For example, you might plot variable importance, investigate the cost of various implementations, and demonstrate some example predictions to showcase the product.
Hex makes collaborating with your teams easy. Gone are the days of sending a few images over Slack and hoping your audience understands you. Instead, you can create full narratives using text cells, or even provide interactivity to help your stakeholders better understand the implications of various design decisions such as thresholds for scores.
You can also share your notebook with your colleagues for review. Those on the data team can validate your work, ask questions, and ask for clarification where they're not sure about a particular technique or design choice.
For stakeholders, you can build an app on your notebook to expose more high-level results, such as model performance, results, and examples. You can start to build interactive applications for your SDRs before going through the trouble of deploying your models into production.
For instance, you could fetch live data from your warehouse on recent leads, run the prediction in your notebook, and show predictions for the 50 latest leads. Before deploying the model, ask your SDRs what they think of the results and iterate. For example, you might learn that they prefer a binary outcome to a probability or that a percentage is more intuitive than a floating decimal.
Iterate and collaborate before deploying your final model to production to save time and effort.
Deploy and Learn
Once your model is trained and set, the last step is to deploy it into production. Deploying models will depend on the existing infrastructure you have. Some companies prefer to handroll their deployments using APIs and containers, while others use managed services. Regardless of how you choose to deploy, don't think your job ends with deployment.
Keep an eye on your models and results, and assess their usage. Spend the next few weeks looking into reports on your SDRs and who they outbound. Talk to them and ask about their behaviors. Monitor your models' performance over time to ensure they don't drift; if they do, consider retraining them. You shouldn't waste the opportunity to learn from your predictions. You put all this hard work into helping your SDRs perform at their best, if they lose faith in the system, they will inevitably revert to their initial gut-feel approach.
Final Words
I hope this has been a helpful introduction to lead scoring. We covered everything from talking to your stakeholders, understanding the business use case, collecting data, building models, assessing performance, and using tools like Hex to accelerate collaboration and iteration speed.
Have you had success with lead scoring models in the past? Reach out to [email protected]; we'd love to hear from you!