A quick foreword: Last year we raised a little bit of money, and we used it to build a lot of software. It could technically be correlation, not causation, but we're feeling pretty good about it, so we raised some more money. If you want to hear more about that money stuff, head over to our Series A announcement. If you're coming from the Series A announcement looking for the real data-nerd content: Welcome to the data-nerd zone :)
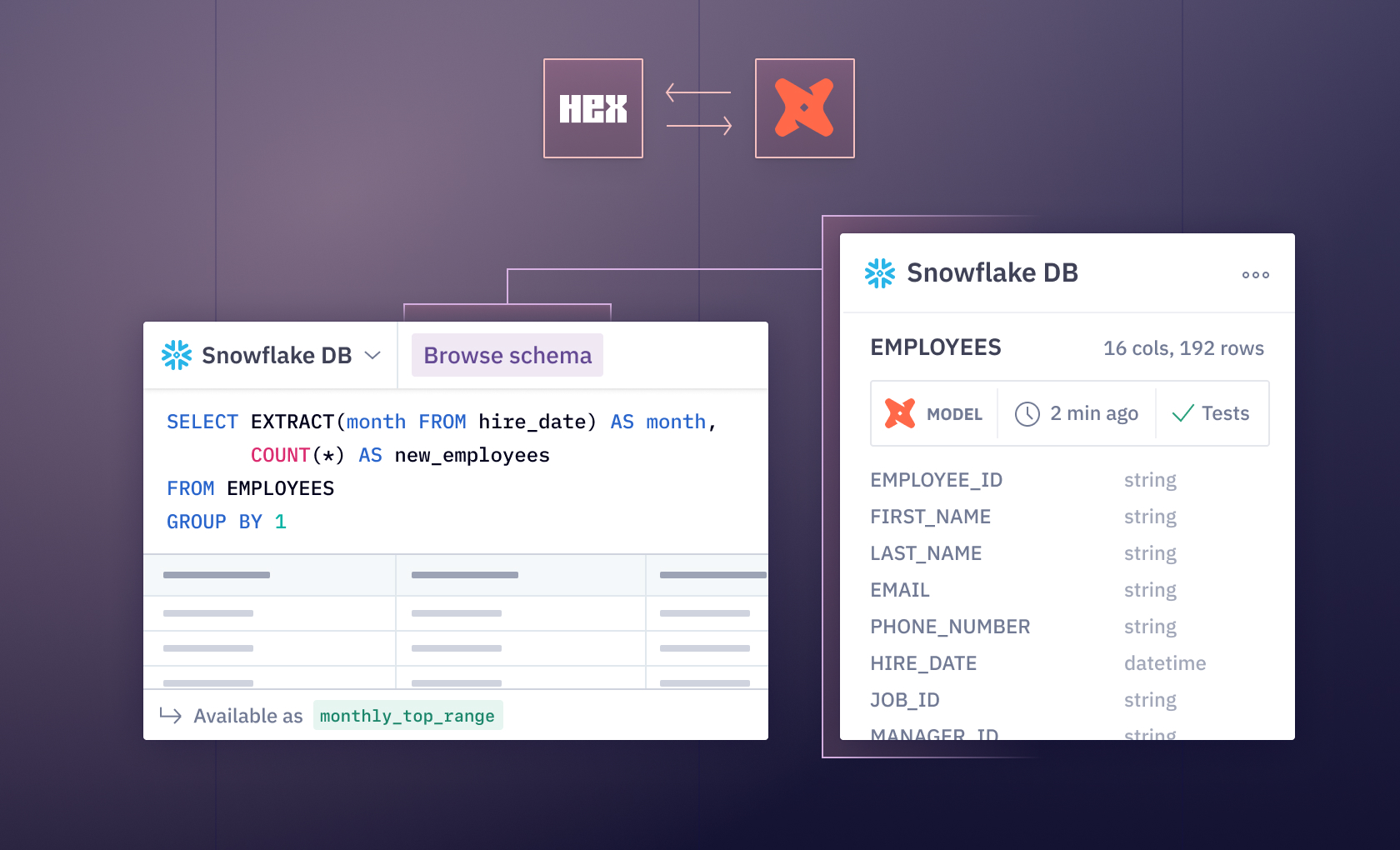
Today we are announcing a really exciting integration with none other than everyone's favorite lowercase-only data transformation tool: dbt. Teams can now connect Hex to their dbt Cloud instance and automatically enrich schemas in Hex with table metadata like freshness and test status. This lets users quickly get the context they need on their data without juggling multiple apps and browser tabs. Exposing this metadata right in the analytics workspace improves trust in data sources, and means analysts don't have to take it on faith that invisible processes are keeping things up to date. It also hopefully reduces the number of SELECT MAX(created_at) FROM possibly_stale_table queries that analysts need to run.
Already use Hex & dbt and want to jump straight in? Here's the docs.
The shoulders of giants
The "Modern Data Stack" of tools is split across a few horizontal layers through which data flows: ingestion, storage, transformation, and analytics (or consumption). 1 Hex sits in the analytics layer, where we are embracing the clean lines between layers by building an extremely powerful and flexible data workspace with fewer constraints than other tools. We feel pretty good about this mission, and the sighs of relief and excitement we see every day from users keeps us confident that we're on the right path.
But we stand on the shoulders of giants. We are making a big bet on the power of embracing flexibility and freedom at the analytics layer by entrusting nearly all of the extremely important work of transformation, governance, and metrics to the upstream layers. This makes it especially exciting for us to officially partner with dbt Labs, because dbt... pretty much completely solves the transformation layer.
Of course, you have always been able to use dbt with Hex. dbt works stoically behind the scenes to produce great, trusted datasets that live in your data warehouse, Hex connects to the warehouse and lets you do analysis, kaboom. Many of our users already do this, and you could do this with any SQL runner or BI tool. The problems that we are addressing with this integration are observability and trust. Just because a table is named great_orders_table_from_dbt doesn't mean that the pipeline backing it hasn't failed and is 4 days out of date. Just because your query runs successfully doesn't mean that upstream tests haven't failed and the data is flat out wrong.
The issue is that while data flows neatly through the layers of the stack, metadata generally doesn't. Most SQL IDEs, BI tools, and data workspaces don't provide the person actually using the data any window into the status of the processes generating and transforming it. They're expected to mostly just take it on faith that those processes exist and are running properly.
But analytical people hate taking things on faith! It's kind of our entire job to not do that! This means that the first queries a lot of people (myself included) write are often simple explorations just to make sure they're working with fresh, reasonable data. You can try to conveniently wave this away as part of "exploratory data analysis", but it's not. It's busy work, unnecessary work that distracts from the creativity of actual data analysis. From verifying freshness to validating data types and column format consistency, a lot of people end up spending an unacceptable amount of time just verifying that their data is all good to go. Sometimes they do end up just running on faith.
With this first version of our dbt integration, we now carry key metadata through from the transformation to the analytics layer. When configured, Hex's schema browser will now show information from dbt on freshness, recent job executions, and test status right on each table. It's a simple addition that reduces mental load and lets data practitioners stay in the creative flow state where they do their best work.
We're just getting started
This work is only the first step in a much bigger bet on the potential to bring information from the metrics and transformation layers closer to the actual analytics layer, while keeping that analytics workspace extremely flexible. We think there's great power in a relatively unconstrained analytics layer that can consume data from diverse sources and remain knowledgeable about metadata from the upstream layers.
Today, we're bringing freshness & test status information from dbt Cloud into Hex. There's still huge opportunities for integration and metadata exchange: Exposures (where else is this data being used?), analyses (could compiled analytical SQL be pushed/pulled straight into Hex?), documentation (what even are these columns that I'm querying?), and of course, at some future time, metrics 😉. We already have many shared customers (including dbt Labs themselves!) and are looking forward to deepening this integration and continuing to partner with the lovely folks at dbt Labs.